Unlocking the Power of Language: Leveraging Large Language Models for Next-Gen Semantic Search and Real-World Applications
Invited talk at Calfus, Pune, June 20, 2024.

Invited talk at Calfus, Pune, June 20, 2024.

It is vital for a company to continuously monitor the changing business landscape for both threats and opportunities. This critical function involves prospecting opportunities and gathering intelligence on competitors, which is then synthesized by analysts into executive briefs with actionable recommendations. This task entails sifting through a wide array of information from diverse sources such as websites, regulatory filings, social media, and news articles, contributed by journalists, analysts, influencers, regulators, as well as internal company staff and officers. Automation efforts have often focused on casting a wider net, resulting in more pressure on downstream analysis and insight generation where the value lies. Recent rapid developments in Generative AI and the emergence of Large Language Models (LLMs) in Open Source have opened the door to automation of these downstream activities. In particular, the “co-pilot” mode of assistive AI offers the potential to increase productivity and reduce the risk of missed opportunities. We built a chatbot assistant in one such use-case for Bayer Crop Science USA.
The challenges of automating information digestion for insight generation can be distilled into two key problems: retrieving relevant information from a large corpus and using that information to contextualize responses. To address the first challenge, we employed Semantic Search, which allows natural language queries to be posed to a large text corpus, yielding ranked results. For the second challenge, we adopted Retrieval Augmented Generation (RAG), a technique that leverages Semantic Search results to provide transient context to a pre-trained Large Language Model (LLM) like ChatGPT. This approach avoids the computational intensity of fine-tuning LLMs and ensures that responses are guided by recent and relevant information without permanently embedding it into the neural network.
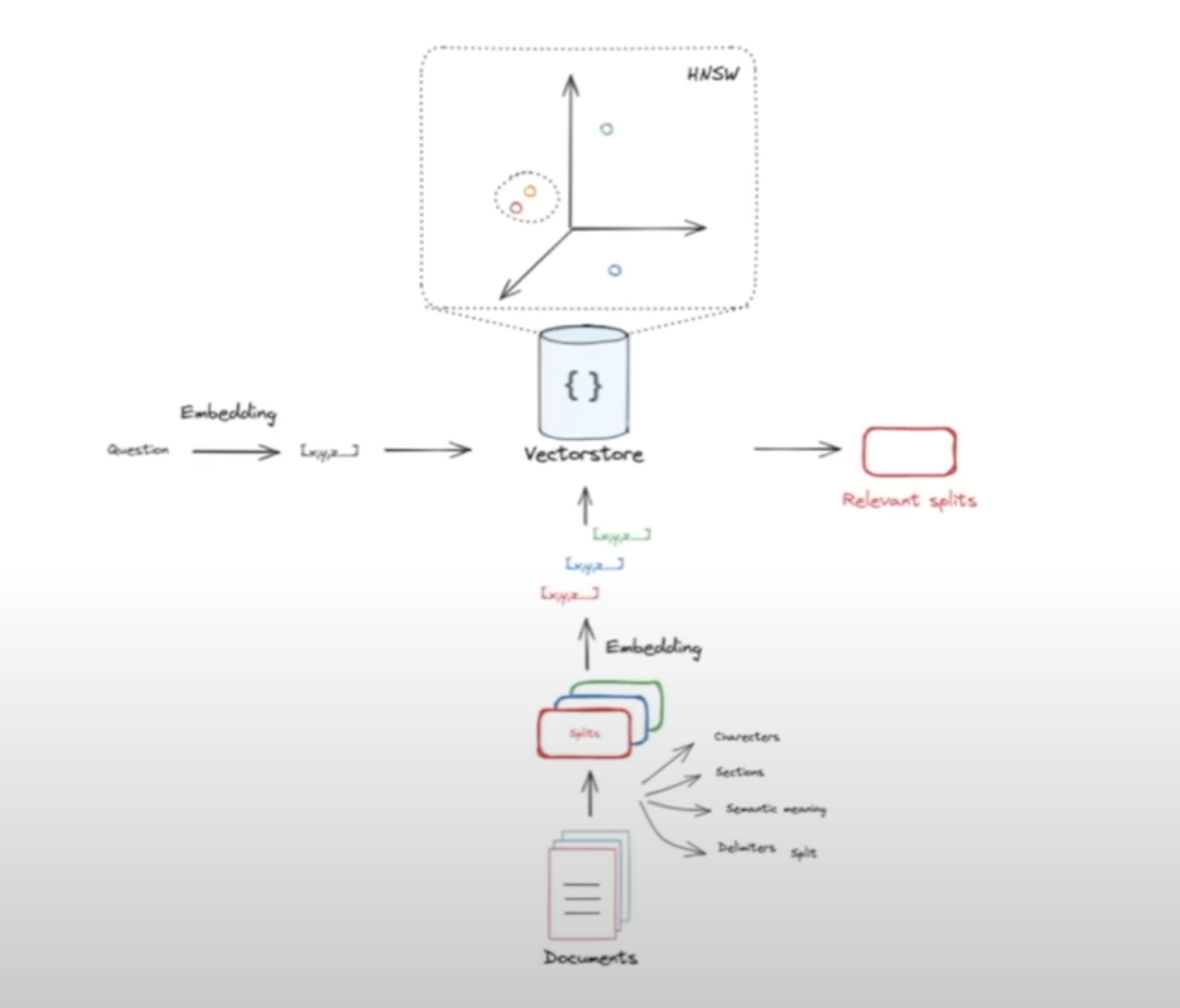
Retrieval Augmented Generation (RAG) utilizes text retrieved by Semantic Search to augment a Large Language Model’s response to a prompt. Semantic Search employs embeddings, which represent text in a vector space. We implemented Semantic Search using the nomic-embed-text model within the ollama framework with Chroma as vector store. We wrapped a Streamlit UI around the vector store to enable search in a “standalone” mode. We used the LangChain framework to pull together the Retrieval Augmented Generation (RAG) workflow, with the Llama2 LLM from Meta with 13B parameters. The user’s prompt is routed to the Semantic Search engine to retrieve relevant documents, which then serve as context for the LLM to use in responding. This approach enhances the LLM’s ability to provide informed responses, effectively supporting the team’s work. The system has been lauded by users at Bayer Crop Science USA, who appreciate its capacity to provide tailored insights and streamline decision-making processes.
Empower yourself with the transformative capabilities of Deep Learning AI through our comprehensive coaching program centered on FastAI. Dive deep into the intricacies of AI and emerge equipped with invaluable skills in natural language processing, computer vision, and beyond. Our hands-on approach ensures that learners of all levels, from beginners to seasoned practitioners, grasp complex concepts with ease and confidence. Join us on a journey of discovery and mastery, where cutting-edge knowledge meets practical application, propelling you towards success in the dynamic world of AI.

What is notable about this collection of names?
ann.
akela.
az.
arileri.
chaiadayra
They share a common origin – each one was generated by a Deep Learning model. Intrigued to understand how? Large Language Models (LLMs) are multifaceted, handling complex tasks such as sentence completion, Q&A, text summarization, and sentiment analysis. LLMs, emphasizing their substantial size, are intricate models with tens or hundreds of billions of parameters, honed on vast datasets totaling 10 terabytes. However, it is possible to appreciate the foundation of how machines learn meaning from text starting from a seemingly straightforward concept – the bigram model.
The bigram model operates on the principle of predicting one token from another. For simplicity, let’s consider tokens as characters in the English alphabet. This principle closely aligns with the essence of LLMs like ChatGPT, which predict subsequent tokens based on preceding ones, iteratively generating coherent text and even entire computer programs. In our bigram model, however, we predict one character from the next, utilizing a 26×26 matrix of probabilities. Each entry in the matrix represents the probability of a particular character appearing after another. This matrix, with some modifications, constitutes our model. Our goal? To generate names.

We introduce an extra character to mark the start or end of a word, expanding from a 26×26 matrix to a 27×27 matrix. The matrix entries arise from patterns observed in a training dataset comprising over 30,000 names from a public database. Raw occurrence counts shown are transformed into probabilities for sampling. Generating a name involves starting with the character that marks the start of a word, sampling the 1st character from the multinomial probability distribution in the 1st row, recycling that character as input to predict the 2nd character, and so forth until reaching the end character. The resulting names, like junide, janasah, p, cony, and a, showcase the model’s unique outputs.
Considering these names, one might favor Janasah! But there’s room for enhancement. Enter the neural network! How would this transition occur? Instead of relying on a lookup matrix, the neural network would predict one character from another. Here’s how:
Refer to the Colab notebook for the implementation with detailed notes. So we have trained a neural network to do what we could do with a matrix. What’s the big deal?
For one, we can use a longer sequence of characters as input to the neural network, giving the model more material to work with to make better predictions. This block of characters provides not just one sequence, but all sequences including and up to the last character as context to the neural network. This already goes beyond what we can do with matrices with counts of occurrences of bigrams.
But how does a neural network learn meaning in text? Part of the answer lies in embeddings. Every token is converted into a numerical vector of fixed size, thus allowing a spatial representation in which meaningful associations can take shape. We allow the embeddings to emerge as properties of a neural network during the training process. The deeper layers of the neural network use these associations as stepping stones to enrich structure in keeping with the nuances and intricacies of linguistic constructs.
Talk about layered meaning!
Wrapping up our baby steps in language models, we’ve transitioned from basic bigram models to deep neural networks, exploring the evolution from mechanical predictions to embeddings that allow associations that capture primitives of nuanced linguistic structure. We get a glimpse into the potential of these models to grasp the intricacies of language, beyond generating names. As we take these initial steps, the horizon of possibilities widens, promising not only enhanced language generation but also advancements in diverse applications, hinting at a future where machines engage with human communication in increasingly sophisticated ways.
Explore the fascinating world of Artificial Intelligence in my upcoming class, powered by FastAI! We’ll embark on a hands-on journey through the evolving landscape of AI, building models with state-of-the-art architecture and learning to wield the power of Large Language Models (LLMs). Whether you’re a beginner or seasoned enthusiast, this class promises a dynamic and engaging exploration into the realm of AI, equipping you with the skills to navigate and innovate in this rapidly evolving field. Join me for an exciting learning experience that goes beyond theory, fueled by the practical insights and advancements offered by FastAI.

In Building a Simple Neural Network From Scratch in PyTorch, we described a recipe with 6 functions as follows:
train_model(epochs=30, lr=0.1): This function acts as the outer wrapper of our training process. It requires access to the training data, trainingIn and trainingOut, which should be defined in the environment. train_model orchestrates the training process by calling the execute_epoch function for a specified number of epochs.execute_epoch(coeffs, lr): Serving as the inner wrapper, this function carries out one complete training epoch. It takes the current coefficients (weights and biases) and a learning rate as input. Within an epoch, it calculates the loss and updates the coefficients. To estimate the loss, it calls calc_loss, which compares the predicted output generated by calc_preds with the target output. After this, execute_epoch performs a backward pass to compute the gradients of the loss, storing these gradients in the grad attribute of each coefficient tensor.calc_loss(coeffs, indeps, deps): This function calculates the loss using the given coefficients, input predictors indeps, and target output deps. It relies on calc_preds to obtain the predicted output, which is then compared to the target output to compute the loss. The backward pass is subsequently invoked to compute the gradients, which are stored within the grad attribute of the coefficient tensors for further optimization.calc_preds(coeffs, indeps): Responsible for computing the predicted output based on the given coefficients and input predictors indeps. This function follows the forward pass logic and applies activation functions where necessary to produce the output.update_coeffs(coeffs, lr): This function plays a pivotal role in updating the coefficients. It iterates through the coefficient tensors, applying gradient descent with the specified learning rate lr. After each update, it resets the gradients to zero using the zero_ function, ensuring the gradients are fresh for the next iteration.init_coeffs(n_hidden=20): The initialization function is responsible for setting up the initial coefficients. It shapes each coefficient tensor based on the number of neurons specified for the sole hidden layer.model_accuracy(coeffs): An optional function that evaluates the prediction accuracy on the validation set, providing insights into how well the trained model generalizes to unseen data.In this blog post, we’ll take a deep dive into constructing a powerful deep learning neural network from the ground up using PyTorch. Building upon the foundations of the previous simple neural network, we’ll refactor some of these functions for deep learning.
Initializing Weights and Biases
To prepare our neural network for deep learning, we’ve revamped the weight and bias initialization process. The init_coeffs function now allows for specifying the number of neurons in each hidden layer, making it flexible for different network configurations. We generate weight matrices and bias vectors for each layer while ensuring they are equipped to handle the deep learning challenges.
def init_coeffs(hiddens=[10, 10]):
sizes = [trainingIn.shape[1]] + hiddens + [1]
n = len(sizes)
weights = [(torch.rand(sizes[i], sizes[i+1]) - 0.3) / sizes[i+1] * 4 for i in range(n-1)] # Weight initialization
biases = [(torch.rand(1)[0] - 0.5) * 0.1 for i in range(n-1)] # Bias initialization
for wt in weights: wt.requires_grad_()
for bs in biases: bs.requires_grad_()
return weights, biases
We define the architecture’s structure using sizes, where hiddens specifies the number of neurons in each hidden layer. We ensure that weight and bias initialization is suitable for deep networks.
Forward Propagation With Multiple Hidden Layers
Our revamped calc_preds function accommodates multiple hidden layers in the network. It iterates through the layers, applying weight matrices and biases at each step and introducing non-linearity using the ReLU activation function in the hidden layers and the sigmoid activation in the output layer. This enables our deep learning network to capture complex patterns in the data.
def calc_preds(coeffs, indeps):
weights, biases = coeffs
res = indeps
n = len(weights)
for i, wt in enumerate(weights):
res = res @ wt + biases[i]
if (i != n-1):
res = F.relu(res) # Apply ReLU activation in hidden layers
return torch.sigmoid(res) # Sigmoid activation in the output layer
Note that weights is now a list of tensors containing layer-wise weights and correspondingly, biases is the the list of tensors containing layer-wise biases.
Backward Propagation With Multiple Hidden Layers
Loss calculation and gradient descent remain consistent with the simple neural network implementation. We use the mean absolute error (MAE) for loss as before and tweak the update_coeffs function to apply gradient descent to update the weights and biases in each hidden layer.
def update_coeffs(coeffs, lr):
weights, biases = coeffs
for layer in weights+biases:
layer.sub_(layer.grad * lr)
layer.grad.zero_()
Putting It All Together in Wrapper Functions
Our train_model function can be used ‘as is’ to orchestrate the raining process using the execute_epoch wrapper function to help as before. The model_accuracy function also does not change.
With these modifications, we’ve refactored our simple neural network into a deep learning model that has greater capacity for learning. The beauty of it is we have retained the same set of functions and interfaces that we implemented in a simple neural network, refactoring the code to scale with multiple hidden layers.
train_model(epochs=30, lr=0.1): No change!execute_epoch(coeffs, lr): No change!calc_loss(coeffs, indeps, deps): No change!calc_preds(coeffs, indeps): Tweak to use the set of weights and corresponding set of biases in each hidden layer, iterating over all layers from input to output.update_coeffs(coeffs, lr): Tweak to iterate over the set of weights and accompanying set of biases in each layer.init_coeffs(hiddens=[10, 10]): Tweak for compatibility with an architecture that can potentially have any number of hidden layers of any size.model_accuracy(coeffs): No change!Such a deep learning model has greater capacity for learning. However, it is is more hungry for training data! In subsequent posts, we will examine the breakthroughs that have made it possible to make deep learning models practically feasible and reliable. These include advancements such as:
Are you eager to dive deeper into the world of deep learning and further enhance your skills?Consider joining our coaching class in deep learning with FastAI. Our class is designed to provide hands-on experience and in-depth knowledge of cutting-edge deep learning techniques. Whether you’re a beginner or an experienced practitioner, we offer tailored guidance to help you master the intricacies of deep learning and empower you to tackle complex projects with confidence. Join us on this exciting journey to unlock the full potential of artificial intelligence and neural networks.

In this blog post, we will walk you through the process of creating a simple neural network from scratch in PyTorch for binary classification. We will implement a neural network with one hidden layer containing multiple neurons followed by a single output neuron. We will also discuss the design choices made for this network, including the use of ReLU activation in the hidden layer and sigmoid activation in the output layer.
Neural Network Architecture
The architecture of our simple neural network can be summarized as follows:
n neurons and ReLU activation.This structure allows us to demonstrate the gradient descent algorithm in PyTorch with multiple iterations of two steps as follows:
We show how PyTorch uses tensors to parallelize operations for efficiency.
Training Data
It is customary to split the available data into three distinct sets: training, validation, and testing. These sets serve specific roles in the model development process.
This partitioning strategy allows for rigorous model assessment and ensures that the model’s performance is accurately estimated on data it has not encountered during training or validation. Before running the code, ensure that trainingIn and trainingOut are defined as global variables. These are represented as tables where rows correspond to individual examples, and each column represents a specific field or feature.
trainingIn contains the independent variables and has the shape (#examples x #variables), where #examples is the number of data points or examples in our training dataset and #variables is the number of independent variables or features.trainingOut contains the dependent variable and has the shape (#examples x 1), where #examples is the same as in trainingInLikewise, we’d want the validationIn and validationOut sets as global variables.
Initializing Weights and Biases
We start by defining the initialization function init_coeffs to set up the initial weights and biases for the neural network. The initialization process includes the following steps:
import torch
def init_coeffs(n_hidden=20):
wt_hidden = (torch.rand(trainingIn.shape[1], n_hidden) - 0.5) / n_hidden
wt_output = torch.rand(n_hidden, 1) - 0.3
bias_output = torch.rand(1)[0]
return wt_hidden.requires_grad_(), wt_output.requires_grad_(), bias_output.requires_grad_()
The key points in this initialization are:
Note that we set requires_grad on weights and biases during initialization. This is a crucial step, as it informs PyTorch to track and compute gradients for these parameters during the subsequent forward and backward passes. When the loss is calculated as a function of weights and biases, PyTorch automatically computes the gradients of the loss with respect to these parameters and stores them for gradient descent optimization.
Forward Pass
Next, we define the function calc_preds to perform the forward pass of the neural network:
import torch.nn.functional as F
def calc_preds(coeffs, indeps):
wt_hid, wt_out, bias = coeffs
hidden_layer_output = F.relu(indeps @ wt_hid)
output = torch.sigmoid(hidden_layer_output @ wt_out + bias)
return output
In this function:
The use of non-linearity is key, Without it, the linear layers are equivalent to a single layer. More importantly, the superposition of non-linearities is what gives the neural network the property of being a universal function approximator. We have chosen ReLU for hidden layer and sigmoid of the output layer, enabling the interpretation of the output as a likelihood score.
Loss Calculation
We calculate the loss using the mean absolute error (MAE) in the calc_loss function:
def calc_loss(coeffs, indeps, deps):
predictions = calc_preds(coeffs, indeps)
loss = torch.abs(predictions - deps).mean()
return loss
Notice that the loss is a function of the weights and biases. By setting requires_grad on these parameters, we inform PyTorch that we are interested in computing the gradients of the loss with respect to these parameters for the purpose of optimization.
Training the Model
To train the neural network, we define the training process using the train_model function:
def train_model(epochs=30, lr=0.1):
torch.manual_seed(442)
coeffs = init_coeffs()
for i in range(epochs):
execute_epoch(coeffs=coeffs, lr=lr)
return coeffs
The train_model function:
execute_epoch for each epoch to update the coefficients.Executing an Epoch
The execute epoch function calculates the loss using calc_loss and propagates the gradients using update_coeffs as follows:
def execute_epoch(coeffs, lr):
loss = calc_loss(coeffs, trainingIn, trainingOut)
loss.backward()
with torch.no_grad():
update_coeffs(coeffs, lr)
print(f'{loss:.3f}', end='; ')
When we call backward on the loss, PyTorch automatically calculates gradients for all the parameters that contribute to the loss and have requires_grad set. These gradients are stored with the respective parameters and can be accessed using the grad attribute.
Updating Coefficients
The update_coeffs function is used to update the coefficients using gradient descent as follows:
def update_coeffs(coeffs, lr):
for layer in coeffs:
layer.sub_(layer.grad * lr)
layer.grad.zero_()
Note that PyTorch accumulates gradients unless these are reset to zero between successive steps. That is why we have zero_ once the gradients are used to update weights and biases.
Running the Training
Finally, we run the training with different learning rates and for varying numbers of epochs:
coeffs = train_model(lr=1.4) # Example 1
coeffs = train_model(lr=20) # Example 2
coeffs = train_model(epochs=100, lr=10) # Example 3
You can observe how the loss changes during training and evaluate the model’s accuracy based on your dataset.
Model Accuracy
Optionally, we can implement a function model_accuracy(coeffs), to evaluate the accuracy of the trained model on the validation dataset.
def model_accuracy(coeffs): return (validationOut.bool() == (calc_preds(coeffs, validationIn) > 0.5)).float().mean()
That’s it! We now have a simple neural network implemented from scratch in PyTorch for binary classification. We can customize the architecture, hyperparameters, and activation functions to suit our specific problem.
train_model() wrapper that requires data cuts trainingIn and trainingOut in the environment. The steps are as follows:train_model(epochs=30, lr=0.1): This function acts as the outer wrapper of our training process. It requires access to the training data, trainingIn and trainingOut, which should be defined in the environment. train_model orchestrates the training process by calling the execute_epoch function for a specified number of epochs.execute_epoch(coeffs, lr): Serving as the inner wrapper, this function carries out one complete training epoch. It takes the current coefficients (weights and biases) and a learning rate as input. Within an epoch, it calculates the loss and updates the coefficients. To estimate the loss, it calls calc_loss, which compares the predicted output generated by calc_preds with the target output. After this, execute_epoch performs a backward pass to compute the gradients of the loss, storing these gradients in the grad attribute of each coefficient tensor.calc_loss(coeffs, indeps, deps): This function calculates the loss using the given coefficients, input predictors indeps, and target output deps. It relies on calc_preds to obtain the predicted output, which is then compared to the target output to compute the loss. The backward pass is subsequently invoked to compute the gradients, which are stored within the grad attribute of the coefficient tensors for further optimization.calc_preds(coeffs, indeps): Responsible for computing the predicted output based on the given coefficients and input predictors indeps. This function follows the forward pass logic and applies activation functions where necessary to produce the output.update_coeffs(coeffs, lr): This function plays a pivotal role in updating the coefficients. It iterates through the coefficient tensors, applying gradient descent with the specified learning rate lr. After each update, it resets the gradients to zero using the zero_ function, ensuring the gradients are fresh for the next iteration.init_coeffs(n_hidden=20): The initialization function is responsible for setting up the initial coefficients. It shapes each coefficient tensor based on the number of neurons specified for the sole hidden layer.model_accuracy(coeffs): An optional function that evaluates the prediction accuracy on the validation set, providing insights into how well the trained model generalizes to unseen data.While we have demonstrated steepest gradient with a simple neural network, we can extend this implementation to a deep learning model by adding more hidden layers. All we need to do is refactor the code keeping the same set of 6 functions and their interfaces. Following the approach presented here, we can create a versatile and scalable neural network architecture tailored to specific requirements.
Are you eager to dive deeper into the world of deep learning and further enhance your skills?Consider joining our coaching class in deep learning with FastAI. Our class is designed to provide hands-on experience and in-depth knowledge of cutting-edge deep learning techniques. Whether you’re a beginner or an experienced practitioner, we offer tailored guidance to help you master the intricacies of deep learning and empower you to tackle complex projects with confidence. Join us on this exciting journey to unlock the full potential of artificial intelligence and neural networks.

Deep learning models have proven their prowess in tasks ranging from identifying objects in images to recognizing handwriting. But what if your data doesn’t come in the form of images? Can you still harness the incredible power of Convolutional Neural Networks (CNNs)? The answer is a resounding “yes,” and today, we’ll explore just how to do that with a captivating example involving heart sounds.
Heart Sounds: Unveiling the Dual-Domain Magic
Heart sounds are typically recorded and can be examined in two fundamental ways: the time domain or the spectral domain. In the time domain, we track how the sound evolves over time, while the spectral domain delves into the sound’s frequency components. Each of these domains reveals a piece of the puzzle, but it’s when we dive into the realm of Wavelet Analysis that the real magic happens.
Wavelet Analysis: Where Time and Frequency Converge
Wavelet Analysis allows us to explore both time and frequency domains simultaneously. Instead of being limited to just one dimension, it combines information from both dimensions, enriching our data with a wealth of details beyond what we can obtain from either time or frequency alone. It’s like putting on 3D glasses for data analysis.
From Dual-Domain Data to Heat-Map Images
Now, here’s where it gets truly fascinating. This dual-domain representation lends itself beautifully to the creation of heat-map images. These images showcase how different frequencies play out over time, resembling a dynamic canvas of information. And guess what? These heat-map images are precisely what we need to tap into the world of CNNs.
CNNs: Ready to Work Their Magic
While CNNs are renowned for their image-processing abilities, they can effortlessly handle these heat-map images derived from heart sounds. There’s no need to reinvent the wheel or build a new model from scratch. With their established architectures like LeNet, AlexNet, GoogLeNet, and ResNet, CNNs become our partners in diagnosing heart defects from murmurs, all thanks to a little creative thinking.
Signal-to-Noise Ratio: A Cautionary Note
Of course, we should exercise caution. Not every image representation is equally informative. Maintaining a high signal-to-noise ratio is critical. We don’t want to obscure our diagnostic insights with unnecessary noise.
In Conclusion: Creativity Meets Cutting-Edge Technology
In the world of deep learning, innovation knows no bounds. Even when dealing with non-image data like heart sounds, we can creatively adapt CNNs to our advantage. No need to start from scratch; we can convert our data into an image format and let CNNs work their magic. This approach opens up exciting avenues for enhancing medical diagnosis and treatment. So, remember, with a little ingenuity, non-image data can also find its place in the world of CNNs.
Our FastAI coaching program at Craft With Code is your passport to mastery of deep learning. Dive into model building, explore real-world data, and transform imaginative concepts into practical solutions. Our hands-on approach guarantees the confidence to tackle a variety of data challenges, with expert guidance from seasoned instructors. Don’t miss out on the opportunity to unlock a world of possibilities—enroll today!”

Gradio’s speed, a digital cruise,
Swift and simple, sparks a muse!
In no time flat, your groove you’ll prove,
With Gradio in your corner, that’s the move.
FastAPI’s power, it rocks the stage,
Shape your endpoints like a sage.
Flexibility is the game it plays,
In countless ways, it’ll amaze for always.
Streamlit’s charm, a sweet compromise,
Stands up your app through day and night’s rise.
It don’t take much coding might, no lies,
Streamlit’s got you covered, that’s so right.
Now, which path will you choose, tech bro?
Take a moment, let your thoughts flow.
Don’t be shy, eat your dogfood, let your app grow,
With these allies, you’ll architect with the know-how.
In our FastAI coaching program, we go beyond the realm of creation. We equip you with the skills not only to build astounding AI applications but also to deploy apps quickly. Imagine the satisfaction of putting your creations directly into the hands of eager users or showcasing them to impress friends and family, or persuade potential employers or investors. You’ll learn to deploy AI in swift and efficient ways, ensuring your innovations make an impact on the world. So, if you’re ready to not just craft AI marvels but get them out there for the world to see, reach out to us on WhatsApp, and let’s embark on this transformative journey together. Your AI-powered future awaits!

Two words. Rest API.
Rest is an acronym that stands for: Representational State Transfer. To put it simply, it’s a protocol that provides a blueprint for organizing data exchanges between machines across the vast landscape of the World Wide Web. Why “representation“? Because we adhere to guidelines in representing data. “State” because data mirrors the ever-evolving state of a system, encapsulating variables that change over time, such as stock market information. And “transfer” because this protocol facilitates the exchange of information.
API is an acronym for Application Programming Interface, with “interface” being the operative term. It’s the digital gateway that enables internet users to interact, whether they’re human or machine. But why the need for such protocols? Picture a world without them, a digital Tower of Babel. Protocols are the glue holding the internet together, the guardians of order in the often chaotic realm of the World Wide Web.
Let’s take a concrete example: Imagine you want to uncover the postal code of Cherrapunji, the renowned record-holder for the world’s highest rainfall. You can achieve this by simply entering its name into a website like worldpostalcode.com. The resulting webpage will pinpoint the postal code on a map, accompanied by relevant details like lat-long coordinates and neighboring postal codes. This seamless exchange of information is orchestrated by a protocol known as HTTP, or Hypertext Transfer Protocol. Any computer equipped with a web browser that ‘speaks’ HTTP can access the website as demonstrated, without any unforeseen hiccups.
But what if your needs extend beyond mere manual inquiries? What if you’re dealing with a deluge of geo-tagged messages, seeking to decode their origins for continuous monitoring? In such cases, the manual approach becomes impractical. This is precisely where the Rest API emerges as a beacon of efficiency. A Rest API, accessed much like a webpage through a URL, responds to your questions with answers. It’s worth noting that sometimes, the answer might be a straightforward “I don’t know!” Each unique query corresponds to a specific URL template known as a Rest API endpoint, as illustrated here: https://app.zipcodebase.com/api/v1/code/city?apikey=YOUR-APIKEY&city=cherrapunji&state_name=meghalaya&country=in.
Let’s unpack this URL, shall we? One notable distinction is “/code/city,” signaling its purpose as the endpoint for city-to-postal code queries. To formulate the URL with this endpoint, we provide parameters such as city, state_name, and country. Can you decipher the role of the “apikey” parameter? Hint: It’s a guardian of security.
The response from a Rest API typically arrives in a format known as JSON (JavaScript Object Notation), appearing something like this:
{
"query":{
"code":"10005",
"unit":"km",
"radius":"10",
"country":"us"
},
"results":[
{
"code":"10005",
"city":"New York",
"state":"NY",
"distance":0
},
{
"code":"10270",
"city":"New York",
"state":"NY",
"distance":0.14
},
{
"code":"10041",
"city":"New York",
"state":"NY",
"distance":0.24
},
...
{
"code":"11102",
"city":"Astoria",
"state":"NY",
"distance":9.99
}
]
}
While it might not appear overly impressive, the true power lies in its versatility. This plain, universal format, devoid of embellishments, makes automation a breeze—precisely why Rest API packs a punch. Furthermore, beyond retrieving information, Rest API encompasses all four of the CRUD verbs: Create, Retrieve, Update, or Delete information remotely. Most programming languages are fluent in JSON, capable of converting it into objects within the programming environment and vice versa, facilitating the exchange referred to as serialization.
Having demystified the Rest API, you can see that exposing Rest API endpoints can place your amazing AI app directly into the hands of users. This opens up a world of possibilities for crafting innovative User Experiences around these endpoints. How easy is it to stand up a Rest API endpoint for your fantastic AI app? Surprisingly straightforward, depending on your choice and flexibility preferences. In future posts, we’ll delve into three options: Gradio, Streamlit, and Fastapi, each with its own trade-offs. Imagine not only learning to build incredible AI apps but also mastering the art of deploying them.
Our FastAI coaching program is your gateway to the cutting-edge realm of artificial intelligence. Here, you’ll wield the power of Python and the enchantment of deep learning to craft AI applications that will astound the world. If you boast at least a year’s worth of Python experience, hesitate no longer. Reach out to us on WhatsApp, and let’s embark on this electrifying journey together.

Six, if you know which ones.
Check out the secret sauce for training a savvy deep learning model to spot pets in pictures:
from fastai.vision.all import *
path = untar_data(URLs.PETS)
dls = ImageDataLoaders.from_name_re(path, get_image_files(path/'images'), pat='(.+)_\d+.jpg', item_tfms=Resize(460), batch_tfms=aug_transforms(size=224, min_scale=0.75))
learn = vision_learner(dls, models.resnet50, metrics=accuracy)
learn.fine_tune(1)
learn.path = Path('.')
learn.export()
When I mentor AI novices, they often do a double-take at how little code it actually takes to kickstart a formidable deep learning machine. People have these wild notions about deep learning, thinking it’s all about:
But here’s the reality check:
Get ready to craft some mind-blowing AI apps in our FastAI coaching program. We’ll arm you with the skills to build top-notch deep learning models. All you need is a minimum of one year’s experience in Python programming. Shoot us a message on WhatsApp now to snag your spot!