Unlocking the Power of Language: Leveraging Large Language Models for Next-Gen Semantic Search and Real-World Applications
Invited talk at Calfus, Pune, June 20, 2024.

Invited talk at Calfus, Pune, June 20, 2024.

It is vital for a company to continuously monitor the changing business landscape for both threats and opportunities. This critical function involves prospecting opportunities and gathering intelligence on competitors, which is then synthesized by analysts into executive briefs with actionable recommendations. This task entails sifting through a wide array of information from diverse sources such as websites, regulatory filings, social media, and news articles, contributed by journalists, analysts, influencers, regulators, as well as internal company staff and officers. Automation efforts have often focused on casting a wider net, resulting in more pressure on downstream analysis and insight generation where the value lies. Recent rapid developments in Generative AI and the emergence of Large Language Models (LLMs) in Open Source have opened the door to automation of these downstream activities. In particular, the “co-pilot” mode of assistive AI offers the potential to increase productivity and reduce the risk of missed opportunities. We built a chatbot assistant in one such use-case for Bayer Crop Science USA.
The challenges of automating information digestion for insight generation can be distilled into two key problems: retrieving relevant information from a large corpus and using that information to contextualize responses. To address the first challenge, we employed Semantic Search, which allows natural language queries to be posed to a large text corpus, yielding ranked results. For the second challenge, we adopted Retrieval Augmented Generation (RAG), a technique that leverages Semantic Search results to provide transient context to a pre-trained Large Language Model (LLM) like ChatGPT. This approach avoids the computational intensity of fine-tuning LLMs and ensures that responses are guided by recent and relevant information without permanently embedding it into the neural network.
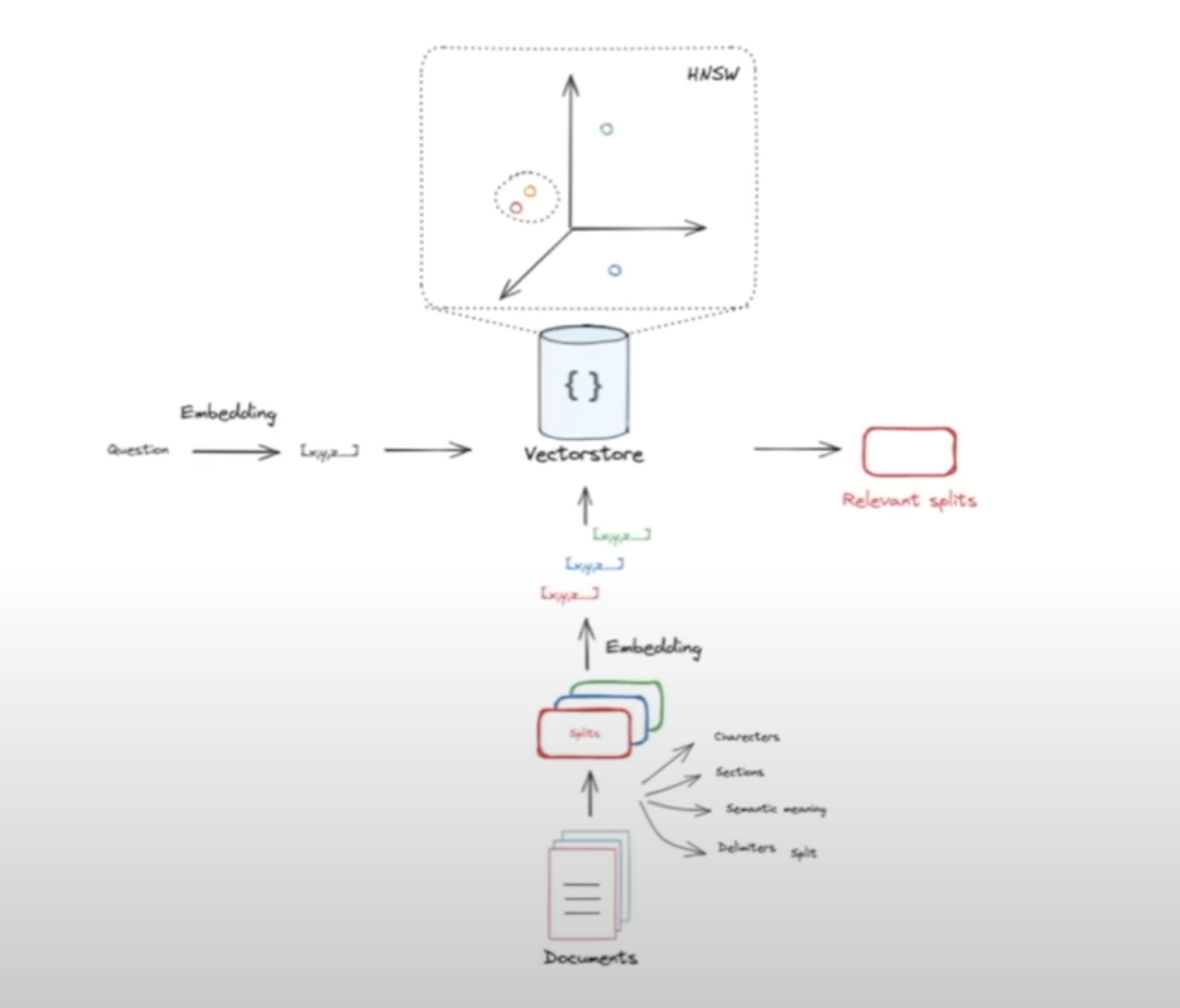
Retrieval Augmented Generation (RAG) utilizes text retrieved by Semantic Search to augment a Large Language Model’s response to a prompt. Semantic Search employs embeddings, which represent text in a vector space. We implemented Semantic Search using the nomic-embed-text model within the ollama framework with Chroma as vector store. We wrapped a Streamlit UI around the vector store to enable search in a “standalone” mode. We used the LangChain framework to pull together the Retrieval Augmented Generation (RAG) workflow, with the Llama2 LLM from Meta with 13B parameters. The user’s prompt is routed to the Semantic Search engine to retrieve relevant documents, which then serve as context for the LLM to use in responding. This approach enhances the LLM’s ability to provide informed responses, effectively supporting the team’s work. The system has been lauded by users at Bayer Crop Science USA, who appreciate its capacity to provide tailored insights and streamline decision-making processes.
Empower yourself with the transformative capabilities of Deep Learning AI through our comprehensive coaching program centered on FastAI. Dive deep into the intricacies of AI and emerge equipped with invaluable skills in natural language processing, computer vision, and beyond. Our hands-on approach ensures that learners of all levels, from beginners to seasoned practitioners, grasp complex concepts with ease and confidence. Join us on a journey of discovery and mastery, where cutting-edge knowledge meets practical application, propelling you towards success in the dynamic world of AI.

Summary: Privacy in the Age of Generative AI
| Synthetic Data | ⇄ | Original Sensitive Information |


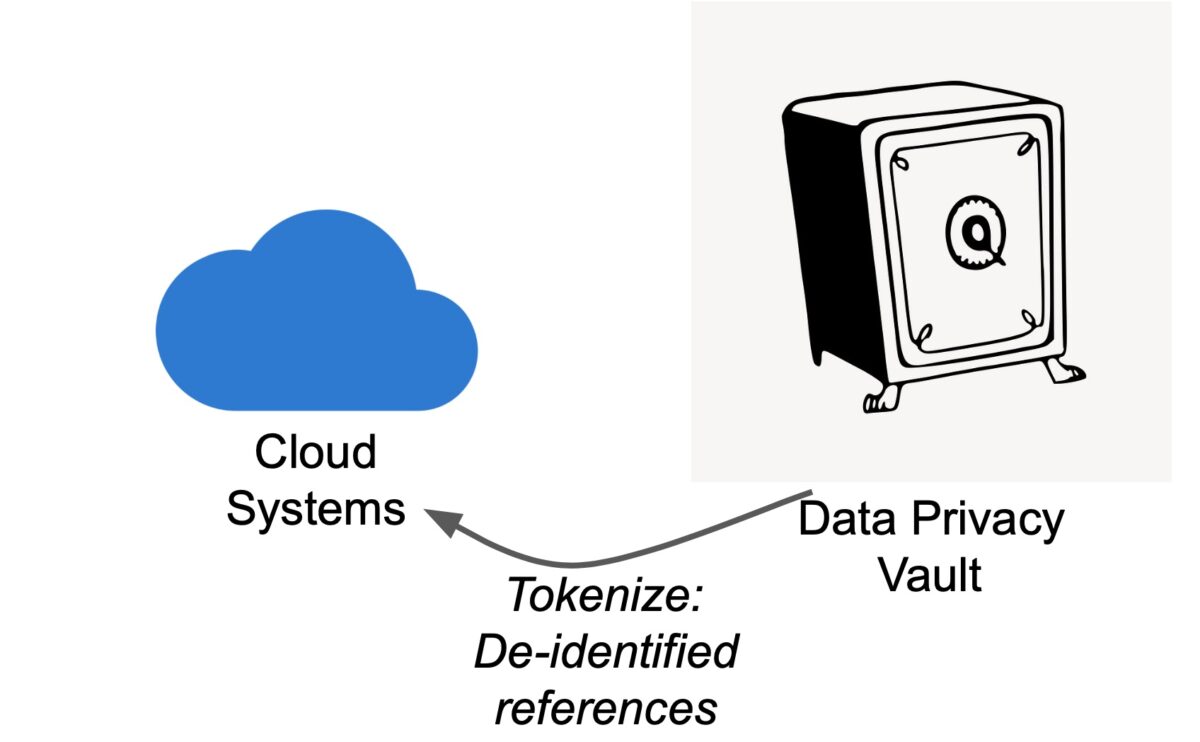

Fig. shows sensitive data under explicit access control to address WHO sees WHAT.

Using privacy enhancing techniques such as polymorphic encryption and tokenization, sensitive data can be de-identified in a way that preserves referential integrity.

🚀 Dive into the cutting-edge world of Artificial Intelligence with my hands-on class using FastAI! In this immersive learning experience, you’ll not only grasp the fundamentals of AI but also explore contemporary challenges and solutions, including the privacy and compliance issues associated with powerful tools like large language models (LLMs). Get hands-on experience with state-of-the-art techniques while unraveling the complexities of generative AI. Join me on this exciting journey to master FastAI and gain insights into the latest advancements in AI technology. Don’t just follow the AI wave—ride it with confidence in my dynamic and practical AI class! 🤖💡 #AI #FastAI #HandsOnLearning #TechInnovation