LLMs have no DELETE button. There is no straightforward mechanism to “unlearn” specific information, no equivalent to deleting a row in your database user table. In a world where “right to be forgotten” is central to many privacy regulations, using LLMs presents some difficult challenges.
Data Privacy Vault is IEEE’s recommended architecture for securely storing, managing and utilizing sensitive customer’s Personally Identifiable Information (PII).
Data of a sensitive nature can seep into LLM during training as well as inference. During training, information of a sensitive na ture may be ingested from documents that are not anonymized or redacted for sensitive information. During inference, a prompt may inadvertently provide sensitive information. For example, a prompt that requests the LLM to summarize a will with sensitive information.
Only way to delete information from an LLM is to train it from scratch! Hence, don’t let sensitive information get in in the first place.
Key consideration for anonymization is Referential Integrity.
Synthetic Data
⇄
Original Sensitive Information
Is private LLM a solution? As opposed to managed service like OpenAI’s ChatGPT. Who will update the base model to keep up with new releases? Expensive!
Base model v. Fine-tuning (Andrej Karpathy’s Intro to Large Language Models)Train an LLM on high volume of low quality data, then fine-tune it with low volume of high quality data. From the YouTube video “Intro to Large Language Models” by Andrej Karpathy.
Private LLM does not address privacy concerns!
Privacy: WHO sees WHATThe expectation of privacy can be summarized in a nutshell as WHO sees WHAT in a corporate data system.
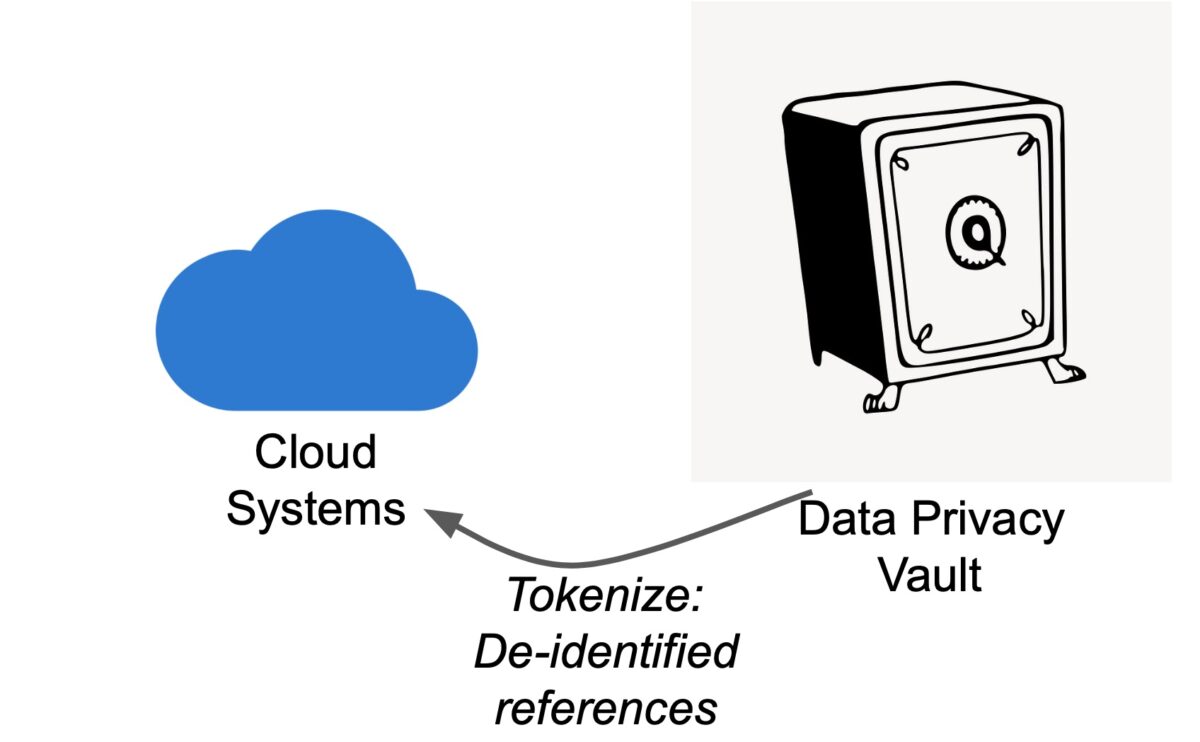
Data Privacy Vault – Principle: The Data Privacy Vault tokenizes personal and other sensitive information in way that preserves referential integrity.
Tokenization: Swap sensitive data for tokens. A token is a reference for some sensitive data somewhere else. Thus, reference something while providing obfuscation.The data ingested via the application frontend has any sensitive data including Personally Identifiable Information (PII) replaced by tokens generated by the Data Privacy Vault.Fig. shows sensitive data being replaced by tokens by the application frontend through the Data Privacy Vault. The assets downstream of the app – app database, warehouse, reports and/or analytics – then only “know” the tokenized data. These are not tokens in the sense of tokenization in LLMs but tokens that hold a reference to the original data which is stored in the Data Privacy Vault.Vault not only stores and generates de-identified data, it tightly controls access to sensitive data through a zero-trust model, where user accounts are managed through explicit access control policies. 777-123-4567 → ABC4567
Fig. shows sensitive data under explicit access control to address WHO sees WHAT.
WHO sees WHAT? The team that has access to the Data Privacy Vault is verifiably in-scope of Identity & Access Management (IAM). Sensitive information can be redacted according to subscriber roles.
Using privacy enhancing techniques such as polymorphic encryption and tokenization, sensitive data can be de-identified in a way that preserves referential integrity.
Prompt Seepage: Sensitive data may also enter a model during inference. For example, a prompt is created asking for a summary of a will. The vault detects the sensitive information, de-identifies it, and shares a non-sensitive version of the prompt with the LLM. Since the LLM was trained on non-sensitive and de-identified data, inference can be carried out as normal.
Data Privacy Vault Architecture
Fig. shows the flow of information in a Data Privacy Vault architecture.
🚀 Dive into the cutting-edge world of Artificial Intelligence with my hands-on class using FastAI! In this immersive learning experience, you’ll not only grasp the fundamentals of AI but also explore contemporary challenges and solutions, including the privacy and compliance issues associated with powerful tools like large language models (LLMs). Get hands-on experience with state-of-the-art techniques while unraveling the complexities of generative AI. Join me on this exciting journey to master FastAI and gain insights into the latest advancements in AI technology. Don’t just follow the AI wave—ride it with confidence in my dynamic and practical AI class! 🤖💡 #AI #FastAI #HandsOnLearning #TechInnovation
They share a common origin – each one was generated by a Deep Learning model. Intrigued to understand how? Large Language Models (LLMs) are multifaceted, handling complex tasks such as sentence completion, Q&A, text summarization, and sentiment analysis. LLMs, emphasizing their substantial size, are intricate models with tens or hundreds of billions of parameters, honed on vast datasets totaling 10 terabytes. However, it is possible to appreciate the foundation of how machines learn meaning from text starting from a seemingly straightforward concept – the bigram model.
The bigram model operates on the principle of predicting one token from another. For simplicity, let’s consider tokens as characters in the English alphabet. This principle closely aligns with the essence of LLMs like ChatGPT, which predict subsequent tokens based on preceding ones, iteratively generating coherent text and even entire computer programs. In our bigram model, however, we predict one character from the next, utilizing a 26×26 matrix of probabilities. Each entry in the matrix represents the probability of a particular character appearing after another. This matrix, with some modifications, constitutes our model. Our goal? To generate names.
Bigram Matrix
The bigram matrix shows the frequency of occurrence of one token following another (“bigram”) in a given dataset. The tokens here are characters of the English alphabet plus one additional token to mark the start or end of a word. The dataset is a collection of 30,000+ names from a public database. The entry in a cell is the count of occurrences of the character in the column following the character in the row.
We introduce an extra character to mark the start or end of a word, expanding from a 26×26 matrix to a 27×27 matrix. The matrix entries arise from patterns observed in a training dataset comprising over 30,000 names from a public database. Raw occurrence counts shown are transformed into probabilities for sampling. Generating a name involves starting with the character that marks the start of a word, sampling the 1st character from the multinomial probability distribution in the 1st row, recycling that character as input to predict the 2nd character, and so forth until reaching the end character. The resulting names, like junide, janasah, p, cony, and a, showcase the model’s unique outputs.
Considering these names, one might favor Janasah! But there’s room for enhancement. Enter the neural network! How would this transition occur? Instead of relying on a lookup matrix, the neural network would predict one character from another. Here’s how:
Representation: Numerically represent each character for input and output with vectors of length 27, accounting for the extra character.
Data Sets: Divide the data into training, validation, and testing sets to train the model, guard against overfitting, and assess performance.
Loss Function: Utilize negative log-likelihood, common in such scenarios, calculated through a softmax layer to generate a probability distribution.
Training: Adjust model parameters using calculated gradients and backpropagation through the neural network.
Refer to the Colab notebook for the implementation with detailed notes. So we have trained a neural network to do what we could do with a matrix. What’s the big deal?
For one, we can use a longer sequence of characters as input to the neural network, giving the model more material to work with to make better predictions. This block of characters provides not just one sequence, but all sequences including and up to the last character as context to the neural network. This already goes beyond what we can do with matrices with counts of occurrences of bigrams.
But how does a neural network learn meaning in text? Part of the answer lies in embeddings. Every token is converted into a numerical vector of fixed size, thus allowing a spatial representation in which meaningful associations can take shape. We allow the embeddings to emerge as properties of a neural network during the training process. The deeper layers of the neural network use these associations as stepping stones to enrich structure in keeping with the nuances and intricacies of linguistic constructs.
Talk about layered meaning!
Wrapping up our baby steps in language models, we’ve transitioned from basic bigram models to deep neural networks, exploring the evolution from mechanical predictions to embeddings that allow associations that capture primitives of nuanced linguistic structure. We get a glimpse into the potential of these models to grasp the intricacies of language, beyond generating names. As we take these initial steps, the horizon of possibilities widens, promising not only enhanced language generation but also advancements in diverse applications, hinting at a future where machines engage with human communication in increasingly sophisticated ways.
Explore the fascinating world of Artificial Intelligence in my upcoming class, powered by FastAI! We’ll embark on a hands-on journey through the evolving landscape of AI, building models with state-of-the-art architecture and learning to wield the power of Large Language Models (LLMs). Whether you’re a beginner or seasoned enthusiast, this class promises a dynamic and engaging exploration into the realm of AI, equipping you with the skills to navigate and innovate in this rapidly evolving field. Join me for an exciting learning experience that goes beyond theory, fueled by the practical insights and advancements offered by FastAI.