
Git Up and Git Together

As the saying goes:
“In case of fire: git commit, git push, and leave the building.”
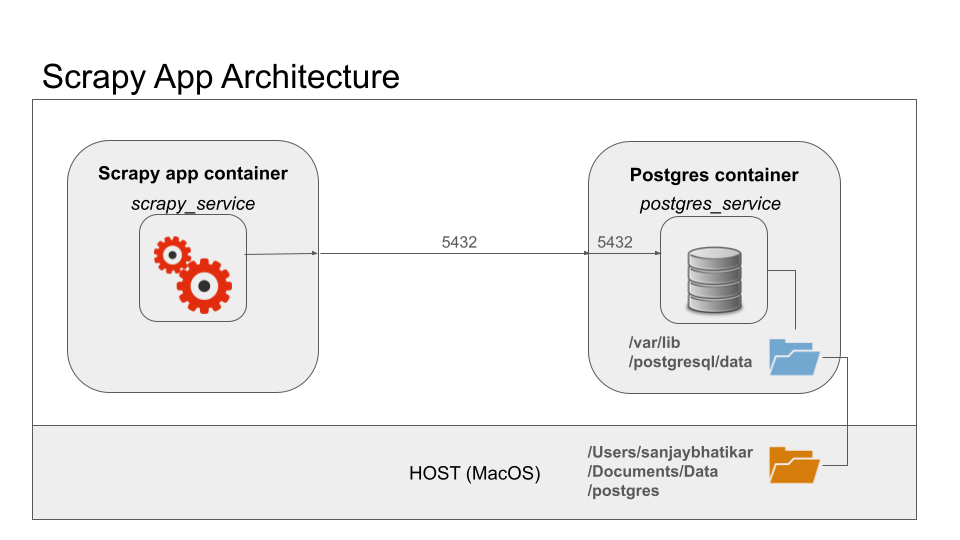
Funny, but in reality, using Git solo is a very different experience from collaborating on a dev team. Here’s a practical mental model to help you manage version control when working in a shared repository—let’s say one named icecap.

🧭 Version Control Workflow (for feature development):
git checkout mainandgit pull
→ Get the latest code from the remote main branch into your local main.git checkout rev00X
→ Switch to your local feature branch (e.g.,rev001,rev002, etc.).git rebase main
→ Update your local feature branch with the latest changes from localmain.- Develop →
git commitandgit push
→ Save progress locally and sync with the remote feature branch.
Repeat steps 1–4 until your feature is ready for review.
- Raise a Pull Request
→ Merge your remote feature branch (rev00X) into the remote main. - Once merged,
git pullon localmainagain
→ Bring your localmainup to date with the remote.
Conclusion Key Takeaways
As a developer, you work with:
- Local branches: your workspace.
- Remote branches: shared team state.
While you’re developing your feature, the remote main is evolving due to contributions from others. To avoid merge conflicts and stay in sync:
- Regularly rebase your feature on the latest
main. - Keep your local and remote branches aligned.
This four-way sync—between local main, local feature, remote main, and remote feature—ensures a smooth, conflict-minimized workflow and clean pull requests.






 Leveraging pre-trained models and neural transfer learning, we curated an extensive in-house dataset comprising 15,000 images meticulously labeled by cell biologists. These images, capturing various stages of embryonic development, were acquired using both an ordinary DSLR camera and a proprietary hyperspectral imaging robot. Our experimentation precisely determined the optimal timeframe for image acquisition post the initiation of plant transformation, establishing that images from a conventional DSLR were on par with those from the hyperspectral camera for the classification task. The impact of our work extends far beyond the confines of the laboratory, catalyzing a wave of innovations in computer vision within biotechnology R&D, spanning laboratories, greenhouses, and field applications. This progressive integration has not only optimized the R&D pipeline but has also significantly accelerated time-to-market, positioning our consultancy at the forefront of transformative advancements in the biotech sector
Leveraging pre-trained models and neural transfer learning, we curated an extensive in-house dataset comprising 15,000 images meticulously labeled by cell biologists. These images, capturing various stages of embryonic development, were acquired using both an ordinary DSLR camera and a proprietary hyperspectral imaging robot. Our experimentation precisely determined the optimal timeframe for image acquisition post the initiation of plant transformation, establishing that images from a conventional DSLR were on par with those from the hyperspectral camera for the classification task. The impact of our work extends far beyond the confines of the laboratory, catalyzing a wave of innovations in computer vision within biotechnology R&D, spanning laboratories, greenhouses, and field applications. This progressive integration has not only optimized the R&D pipeline but has also significantly accelerated time-to-market, positioning our consultancy at the forefront of transformative advancements in the biotech sector


