
An Interesting SQL Query or Two
SQL is described as a primitive programming language. The vocabulary of SQL, while compact, can still work wonders to shape data into a suitable form for visualization. One has only to be creative! Here is an example!
Expense Tracking Use-Case DB and Visualizations
I have an app that records daily expenses. The Postgres DB saves each expense as a line item with the amount and date-time. Further, the expense is annotated with tags in key-value form to describe WHY (purpose of the expense), WHO (vendor engaged), WHERE (transaction location), etc.
I wanted two visualizations as follows:
- Track the cumulative expenses over days of the current month to compare with the previous month’s.
- Track month-month expenses in key categories.
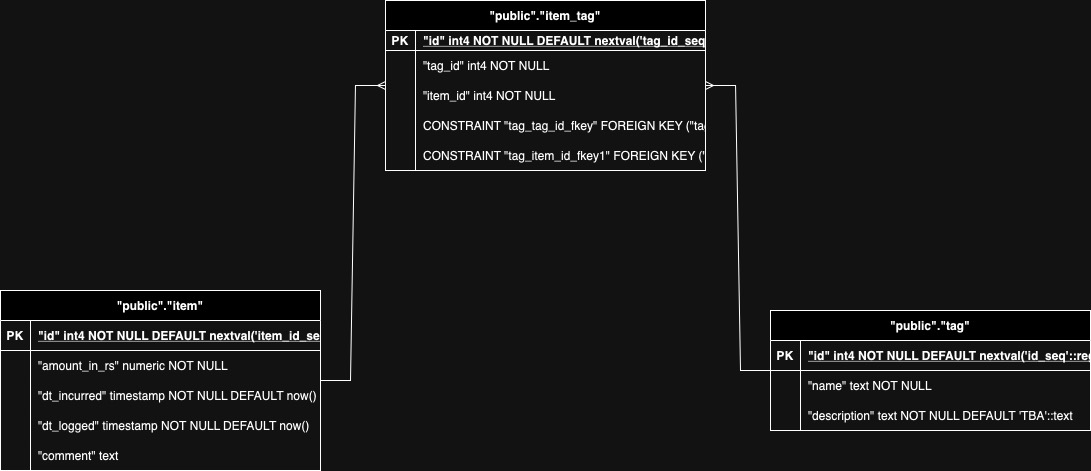
DB Schema for Expense Tracking:
Cumulative Expenses:
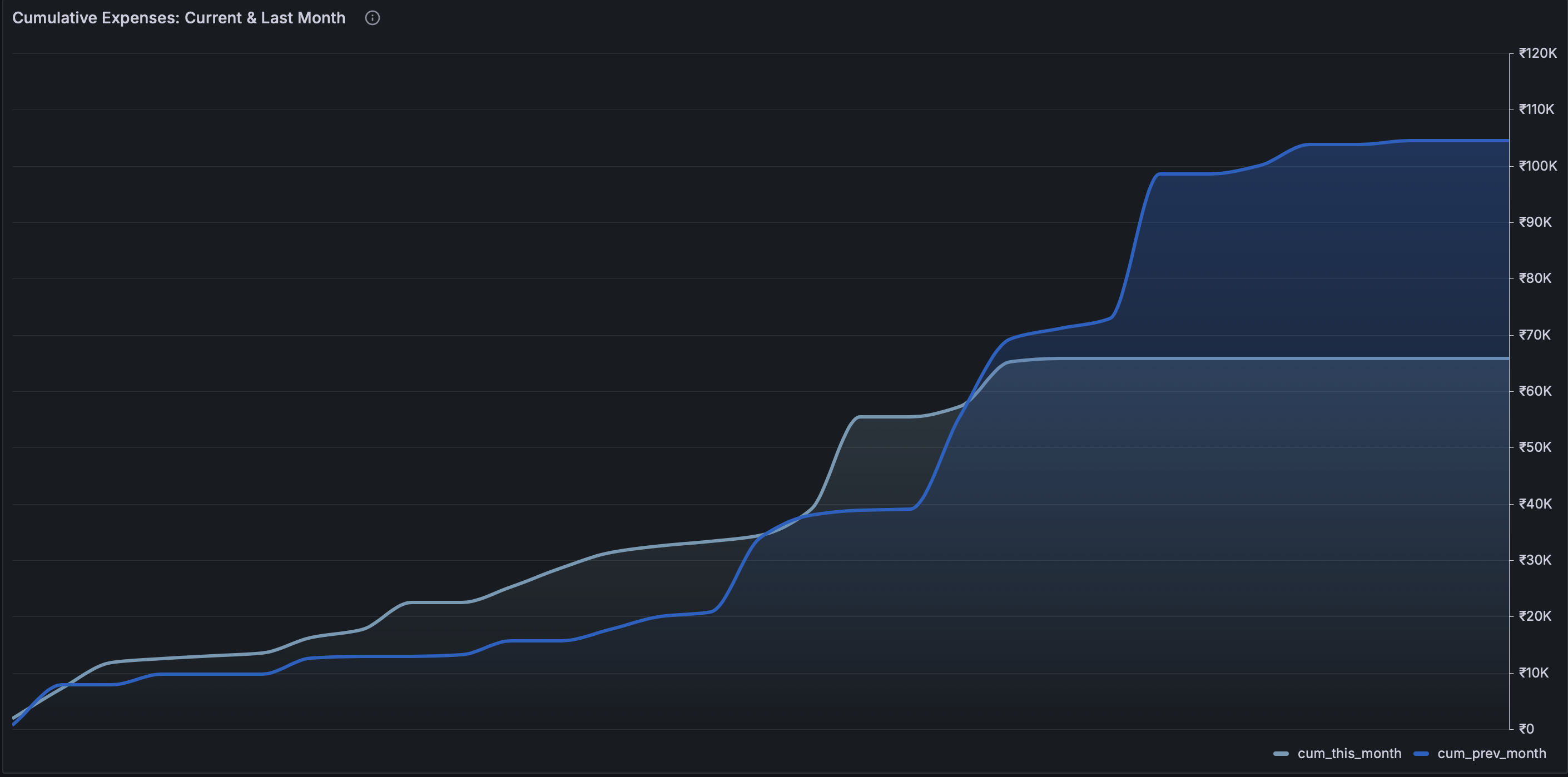
The visualization requires a table with 31 rows for the days of the month and a column with cumulative expenses for current month and another column with the same data for the previous month.
Categorical Expenses:
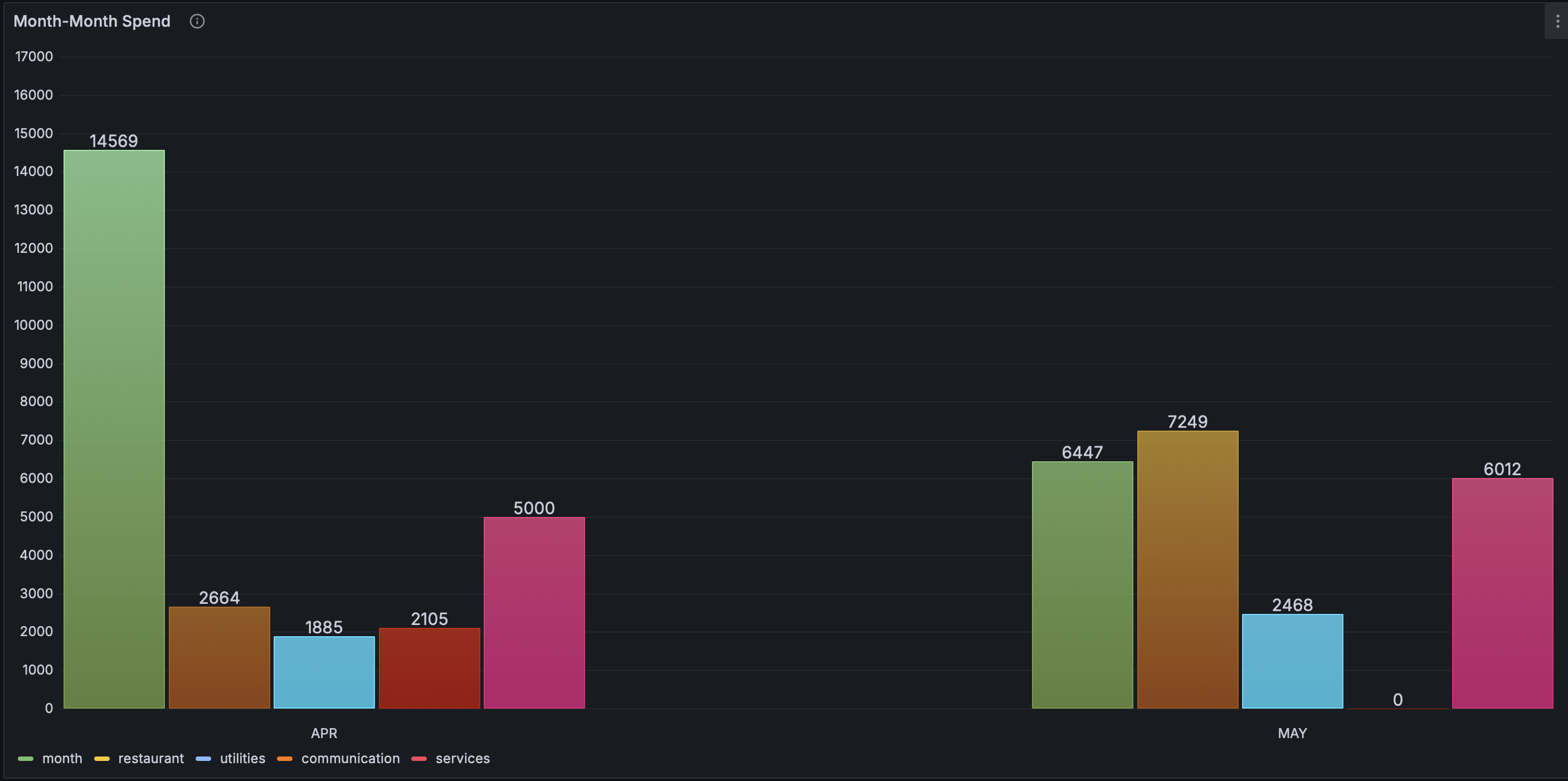
The visualization requires a table with a row for each month to be shown (2 months in the illustration – March, April) and one column for each category in which expenses are summarized.
SQL Pivots Split-Apply-Combine Strategy for Data Analysis
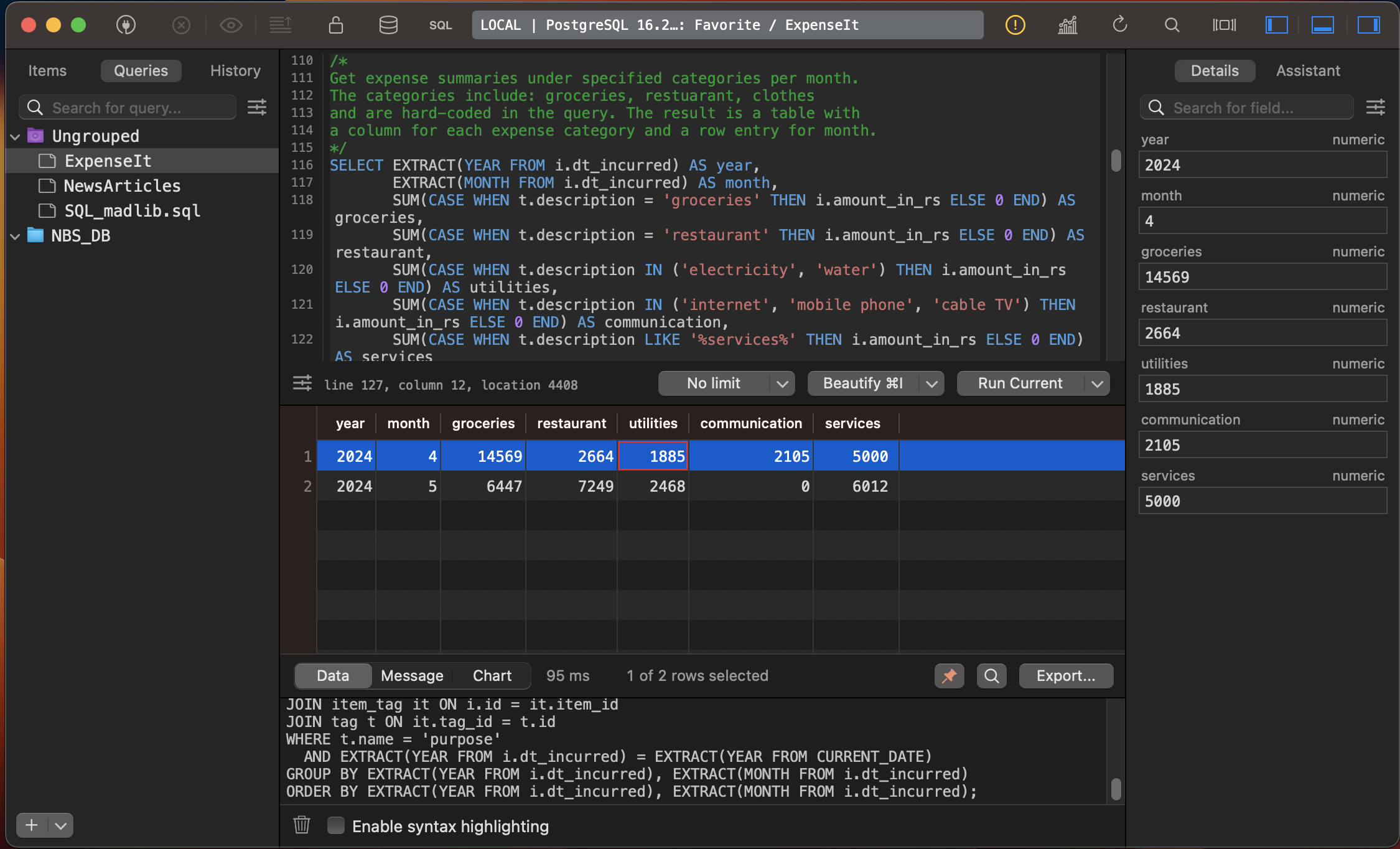
Here is the query for the expense summaries by category for each month.
SELECT EXTRACT(YEAR FROM i.dt_incurred) AS year,
EXTRACT(MONTH FROM i.dt_incurred) AS month,
SUM(CASE WHEN t.description = 'groceries' THEN i.amount_in_rs ELSE 0 END) AS groceries,
SUM(CASE WHEN t.description = 'restaurant' THEN i.amount_in_rs ELSE 0 END) AS restaurant,
SUM(CASE WHEN t.description IN ('electricity', 'water') THEN i.amount_in_rs ELSE 0 END) AS utilities,
SUM(CASE WHEN t.description IN ('internet', 'mobile phone', 'cable TV') THEN i.amount_in_rs ELSE 0 END) AS communication,
SUM(CASE WHEN t.description LIKE '%services%' THEN i.amount_in_rs ELSE 0 END) AS services
FROM item i
JOIN item_tag it ON i.id = it.item_id
JOIN tag t ON it.tag_id = t.id
WHERE t.name = 'purpose'
AND EXTRACT(YEAR FROM i.dt_incurred) = EXTRACT(YEAR FROM CURRENT_DATE)
GROUP BY EXTRACT(YEAR FROM i.dt_incurred), EXTRACT(MONTH FROM i.dt_incurred)
ORDER BY EXTRACT(YEAR FROM i.dt_incurred), EXTRACT(MONTH FROM i.dt_incurred);
This produces the desired table as shown in the figure below.
We can understand this query with a simpler version that takes only one category to summarize expenses in current month.
SELECT SUM(i.amount_in_rs) AS total_amount
FROM item i
JOIN item_tag it ON i.id = it.item_id
JOIN tag t ON it.tag_id = t.id
WHERE t.name = 'purpose'
AND t.description = 'clothes'
AND EXTRACT(MONTH FROM i.dt_incurred) = EXTRACT(MONTH FROM CURRENT_DATE)
AND EXTRACT(YEAR FROM i.dt_incurred) = EXTRACT(YEAR FROM CURRENT_DATE);
The code allows only the current month and year and then selects rows tagged with ‘purpose’ as ‘clothes’. In the final version, we work off the same JOIN and add heft to the query to generate summaries in multiple categories of interest for each month. This is a variation on the Split-Apply-Combine strategy for Data Analysis, where you break up a big problem into manageable pieces, operate on each piece independently and then put all the pieces back together.
The main query builds on this to generate the categorical summaries of each month in the current year that data are available for!
Cumulative Sum Split-Apply-Combine After Self-Join
Here is the query for cumulative sum.
WITH days AS (
SELECT generate_series(1, 31) AS day_of_month
),
current_month_expenses_by_day AS (
SELECT
EXTRACT(DAY FROM dt_incurred) AS day_of_month,
SUM(amount_in_rs) AS daily_expense
FROM item
WHERE EXTRACT(YEAR FROM dt_incurred) = EXTRACT(YEAR FROM CURRENT_DATE)
AND EXTRACT(MONTH FROM dt_incurred) = EXTRACT(MONTH FROM CURRENT_DATE)
GROUP BY EXTRACT(DAY FROM dt_incurred)
),
previous_month_expenses_by_day AS (
SELECT
EXTRACT(DAY FROM dt_incurred) AS day_of_month,
SUM(amount_in_rs) AS daily_expense
FROM item
WHERE EXTRACT(YEAR FROM dt_incurred) = EXTRACT(YEAR FROM CURRENT_DATE - INTERVAL '1 month')
AND EXTRACT(MONTH FROM dt_incurred) = EXTRACT(MONTH FROM CURRENT_DATE - INTERVAL '1 month')
GROUP BY EXTRACT(DAY FROM dt_incurred)
),
current_month_cumulative_expenses AS (
SELECT
d.day_of_month,
COALESCE(e.daily_expense, 0) AS daily_expense
FROM
days d
LEFT JOIN current_month_expenses_by_day e ON d.day_of_month = e.day_of_month
),
previous_month_cumulative_expenses AS (
SELECT
d.day_of_month,
COALESCE(e.daily_expense, 0) AS daily_expense
FROM
days d
LEFT JOIN previous_month_expenses_by_day e ON d.day_of_month = e.day_of_month
)
SELECT
d.day_of_month,
SUM(c.daily_expense) OVER (ORDER BY d.day_of_month) AS cum_this_month,
SUM(p.daily_expense) OVER (ORDER BY d.day_of_month) AS cum_prev_month
FROM
days d
LEFT JOIN current_month_cumulative_expenses c ON d.day_of_month = c.day_of_month
LEFT JOIN previous_month_cumulative_expenses p ON d.day_of_month = p.day_of_month
ORDER BY
d.day_of_month;
It is easier to understand cumulative summation in SQL with a simpler example.
Example to Illustrate:
Assume we have the following table @t:
| id | SomeNumt |
|---|---|
| 1 | 10 |
| 2 | 20 |
| 3 | 30 |
| 4 | 40 |
The query to add a column containing the cumulative sum is as follows:
select
t1.id,
t1.SomeNumt,
SUM(t2.SomeNumt) as sum
from
@t t1
inner join
@t t2
on t1.id >= t2.id
group by
t1.id,
t1.SomeNumt
order by
t1.id;
- Table Aliases:
-
- The table
@tis given aliasest1andt2to allow for a self-join. This is necessary to compare rows within the same table.
- The table
- Self-Join Condition:
-
inner join @t t2 on t1.id >= t2.id- The join condition
t1.id >= t2.idensures that for each row int1, it will match with all rows int2wheret2.idis less than or equal tot1.id. This effectively creates pairs of rows where each row int1will pair with all preceding rows int2including itself.
Join Result:
The self-join on id with the condition t1.id >= t2.id will produce:
| t1.id | t1.SomeNumt | t2.id | t2.SomeNumt |
|---|---|---|---|
| 1 | 10 | 1 | 10 |
| 2 | 20 | 1 | 10 |
| 2 | 20 | 2 | 20 |
| 3 | 30 | 1 | 10 |
| 3 | 30 | 2 | 20 |
| 3 | 30 | 3 | 30 |
| 4 | 40 | 1 | 10 |
| 4 | 40 | 2 | 20 |
| 4 | 40 | 3 | 30 |
| 4 | 40 | 4 | 40 |
- Grouping:
-
group by t1.id, t1.SomeNumt- After the join, the result set is grouped by
t1.idandt1.SomeNumt. This ensures that we calculate the cumulative sum for eachidint1.
- Cumulative Sum Calculation:
-
SUM(t2.SomeNumt) as sum- For each group (each unique
idfromt1), the query calculates the sum ofSomeNumtfrom all the rows int2that are less than or equal to the currentidint1. This effectively gives us the cumulative sum up to the currentid.
Grouping and Summing Result:
Grouping by t1.id and t1.SomeNumt and summing t2.SomeNumt:
| t1.id | t1.SomeNumt | SUM(t2.SomeNumt) |
|---|---|---|
| 1 | 10 | 10 |
| 2 | 20 | 30 |
| 3 | 30 | 60 |
| 4 | 40 | 100 |
This result shows the cumulative sum of SomeNumt up to each id. We have thus found a method of taking cumulative sum in SQL.
Recap:
- For each
idint1, the join finds all preceding rows including itself int2. - The
sumfunction then calculates the total ofSomeNumtfor these rows. - Grouping ensures that this calculation is done separately for each
idint1. - The result is a cumulative sum of
SomeNumtfor eachid, effectively showing how the sum accumulates asidincreases.
While this is a clever solution, it has a downside that the operation has O(n^2) complexity. So the computational effort explodes exponentially. When our table grows to a million rows, we need a different approach!
Cumulative Sum Redux Sum Over Series
SELECT
id,
SomeNumt,
SUM(SomeNumt) OVER (ORDER BY id) AS cumulative_sum
FROM
@t
ORDER BY
id;
Optimized Query:
The optimized query uses the SUM OVER window function:
- The
SUM(SomeNumt) OVER (ORDER BY id)calculates a running total (cumulative sum) ofSomeNumtvalues in the order ofid. - This avoids the need for a self-join and instead uses a window function which is designed to efficiently compute cumulative sums.
Window functions perform a calculation across a set of table rows that are somehow related to the current row. Unlike aggregate functions, window functions do not cause rows to become grouped into a single output row.
How SUM OVER Works:
ORDER BYClause: TheORDER BY idinside theOVERclause specifies the order in which the rows are processed for the sum.- Cumulative Sum: The
SUM(SomeNumt) OVER (ORDER BY id)computes the cumulative sum by adding the current row’sSomeNumtto the sum of all previous rows’SomeNumt.
Efficiency Gains: O(n) Complexity: The window function computes the cumulative sum in a single pass through the data, making it O(n) in complexity, significantly improving performance over the O(n^2) complexity of the self-join.
Cumulative Sum Sum Over Generated Series
Here, then, is how we query the cumulative expense over days of the current month.
/*
Get cumulative expense by day of the month for current month.
*/
WITH days AS (
SELECT generate_series(1, 31) AS day_of_month
),
expenses_by_day AS (
SELECT
EXTRACT(DAY FROM dt_incurred) AS day_of_month,
SUM(amount_in_rs) AS daily_expense
FROM item
WHERE DATE_TRUNC('month', dt_incurred) = DATE_TRUNC('month', CURRENT_DATE)
GROUP BY EXTRACT(DAY FROM dt_incurred)
),
cumulative_expenses AS (
SELECT
d.day_of_month,
COALESCE(e.daily_expense, 0) AS daily_expense
FROM
days d
LEFT JOIN expenses_by_day e ON d.day_of_month = e.day_of_month
)
SELECT
day_of_month,
SUM(daily_expense) OVER (ORDER BY day_of_month) AS cum_this_month
FROM
cumulative_expenses
ORDER BY
day_of_month;
Here is how it works:
WITH days AS (
SELECT generate_series(1, 31) AS day_of_month
)
- Generate Series: This generates a series of days from 1 to 31, covering all possible days in a month.
expenses_by_day AS (
SELECT
EXTRACT(DAY FROM dt_incurred) AS day_of_month,
SUM(amount_in_rs) AS daily_expense
FROM item
WHERE DATE_TRUNC('month', dt_incurred) = DATE_TRUNC('month', CURRENT_DATE)
GROUP BY EXTRACT(DAY FROM dt_incurred)
)
- Aggregate Daily Expenses: This subquery calculates the total expense for each day of the current month by extracting the day part from the
dt_incurredcolumn and summing theamount_in_rs.
cumulative_expenses AS (
SELECT
d.day_of_month,
COALESCE(e.daily_expense, 0) AS daily_expense
FROM
days d
LEFT JOIN expenses_by_day e ON d.day_of_month = e.day_of_month
)
- Combine Days and Expenses: This step ensures that each day of the month is included in the result, even if there were no expenses on that day, by using a left join between the generated days and the aggregated expenses.
SELECT
day_of_month,
SUM(daily_expense) OVER (ORDER BY day_of_month) AS cum_this_month
FROM
cumulative_expenses
ORDER BY
day_of_month;
- Calculate Cumulative Expenses: Finally, this query calculates the cumulative sum of expenses using the SUM() OVER (ORDER BY day_of_month) window function. This computes a running total of the expenses, ordered by the day of the month.
The main query builds on this to calculate the cumulative expenses for the previous month in addition to the current month.
Conclusion SQL Chops
SQL is a technology that is easy to underestimate in the Age of AI, but we do so at our own peril. Particularly when building data pipelines, one can use SQL to reshape data into the form suitable for consumption at the end-point – or as close to it as possible. In the use-case of expense reporting, SQL opened to door to compelling visualizations using templates in Grafana.
Looking to elevate your AI skills? Join our FastAI course! We cover not only cutting-edge modeling techniques but also the essential skills for acquiring, managing, and visualizing data. Learn from Ph.D. instructors who guide you through the entire process, from data collection to impactful visualizations, ensuring you’re equipped to tackle real-world challenges.

