LLMs have no DELETE button. There is no straightforward mechanism to “unlearn” specific information, no equivalent to deleting a row in your database user table. In a world where “right to be forgotten” is central to many privacy regulations, using LLMs presents some difficult challenges.
Data Privacy Vault is IEEE’s recommended architecture for securely storing, managing and utilizing sensitive customer’s Personally Identifiable Information (PII).
Data of a sensitive nature can seep into LLM during training as well as inference. During training, information of a sensitive na ture may be ingested from documents that are not anonymized or redacted for sensitive information. During inference, a prompt may inadvertently provide sensitive information. For example, a prompt that requests the LLM to summarize a will with sensitive information.
Only way to delete information from an LLM is to train it from scratch! Hence, don’t let sensitive information get in in the first place.
Key consideration for anonymization is Referential Integrity.
Synthetic Data
⇄
Original Sensitive Information
Is private LLM a solution? As opposed to managed service like OpenAI’s ChatGPT. Who will update the base model to keep up with new releases? Expensive!
Base model v. Fine-tuning (Andrej Karpathy’s Intro to Large Language Models)Train an LLM on high volume of low quality data, then fine-tune it with low volume of high quality data. From the YouTube video “Intro to Large Language Models” by Andrej Karpathy.
Private LLM does not address privacy concerns!
Privacy: WHO sees WHATThe expectation of privacy can be summarized in a nutshell as WHO sees WHAT in a corporate data system.
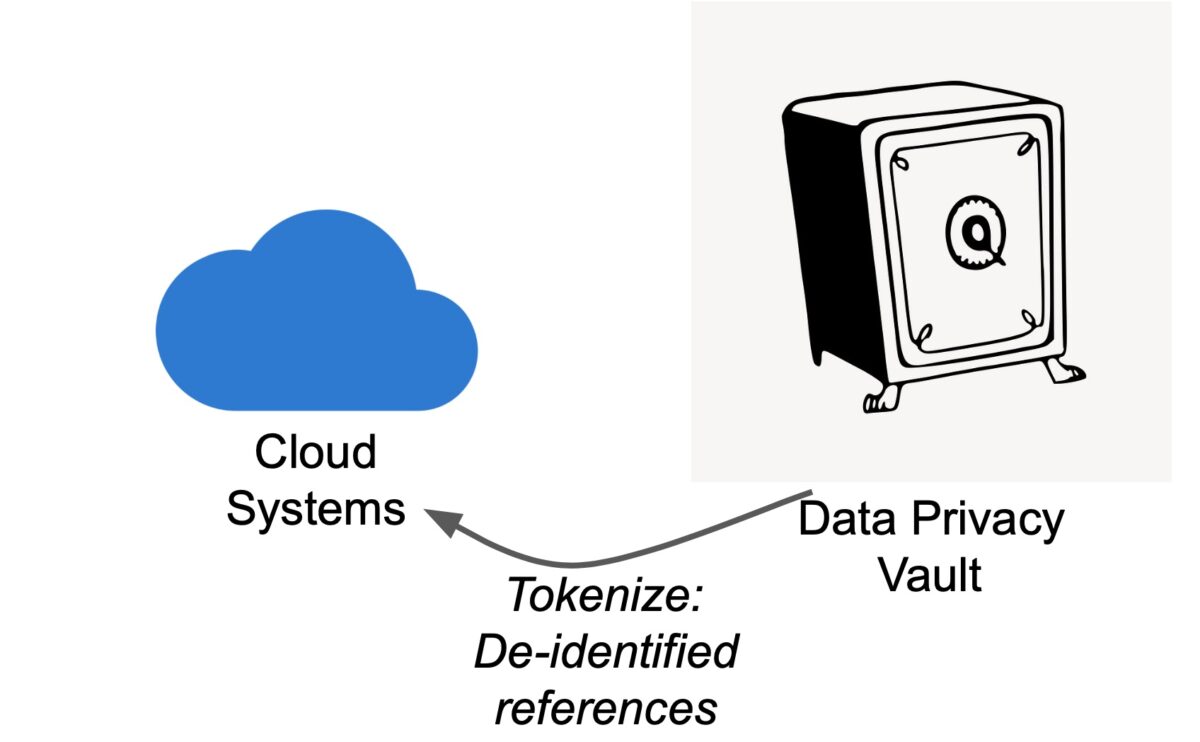
Data Privacy Vault – Principle: The Data Privacy Vault tokenizes personal and other sensitive information in way that preserves referential integrity.
Tokenization: Swap sensitive data for tokens. A token is a reference for some sensitive data somewhere else. Thus, reference something while providing obfuscation.The data ingested via the application frontend has any sensitive data including Personally Identifiable Information (PII) replaced by tokens generated by the Data Privacy Vault.Fig. shows sensitive data being replaced by tokens by the application frontend through the Data Privacy Vault. The assets downstream of the app – app database, warehouse, reports and/or analytics – then only “know” the tokenized data. These are not tokens in the sense of tokenization in LLMs but tokens that hold a reference to the original data which is stored in the Data Privacy Vault.Vault not only stores and generates de-identified data, it tightly controls access to sensitive data through a zero-trust model, where user accounts are managed through explicit access control policies. 777-123-4567 → ABC4567
Fig. shows sensitive data under explicit access control to address WHO sees WHAT.
WHO sees WHAT? The team that has access to the Data Privacy Vault is verifiably in-scope of Identity & Access Management (IAM). Sensitive information can be redacted according to subscriber roles.
Using privacy enhancing techniques such as polymorphic encryption and tokenization, sensitive data can be de-identified in a way that preserves referential integrity.
Prompt Seepage: Sensitive data may also enter a model during inference. For example, a prompt is created asking for a summary of a will. The vault detects the sensitive information, de-identifies it, and shares a non-sensitive version of the prompt with the LLM. Since the LLM was trained on non-sensitive and de-identified data, inference can be carried out as normal.
Data Privacy Vault Architecture
Fig. shows the flow of information in a Data Privacy Vault architecture.
🚀 Dive into the cutting-edge world of Artificial Intelligence with my hands-on class using FastAI! In this immersive learning experience, you’ll not only grasp the fundamentals of AI but also explore contemporary challenges and solutions, including the privacy and compliance issues associated with powerful tools like large language models (LLMs). Get hands-on experience with state-of-the-art techniques while unraveling the complexities of generative AI. Join me on this exciting journey to master FastAI and gain insights into the latest advancements in AI technology. Don’t just follow the AI wave—ride it with confidence in my dynamic and practical AI class! 🤖💡 #AI #FastAI #HandsOnLearning #TechInnovation